Getting Started
HPC Clusters
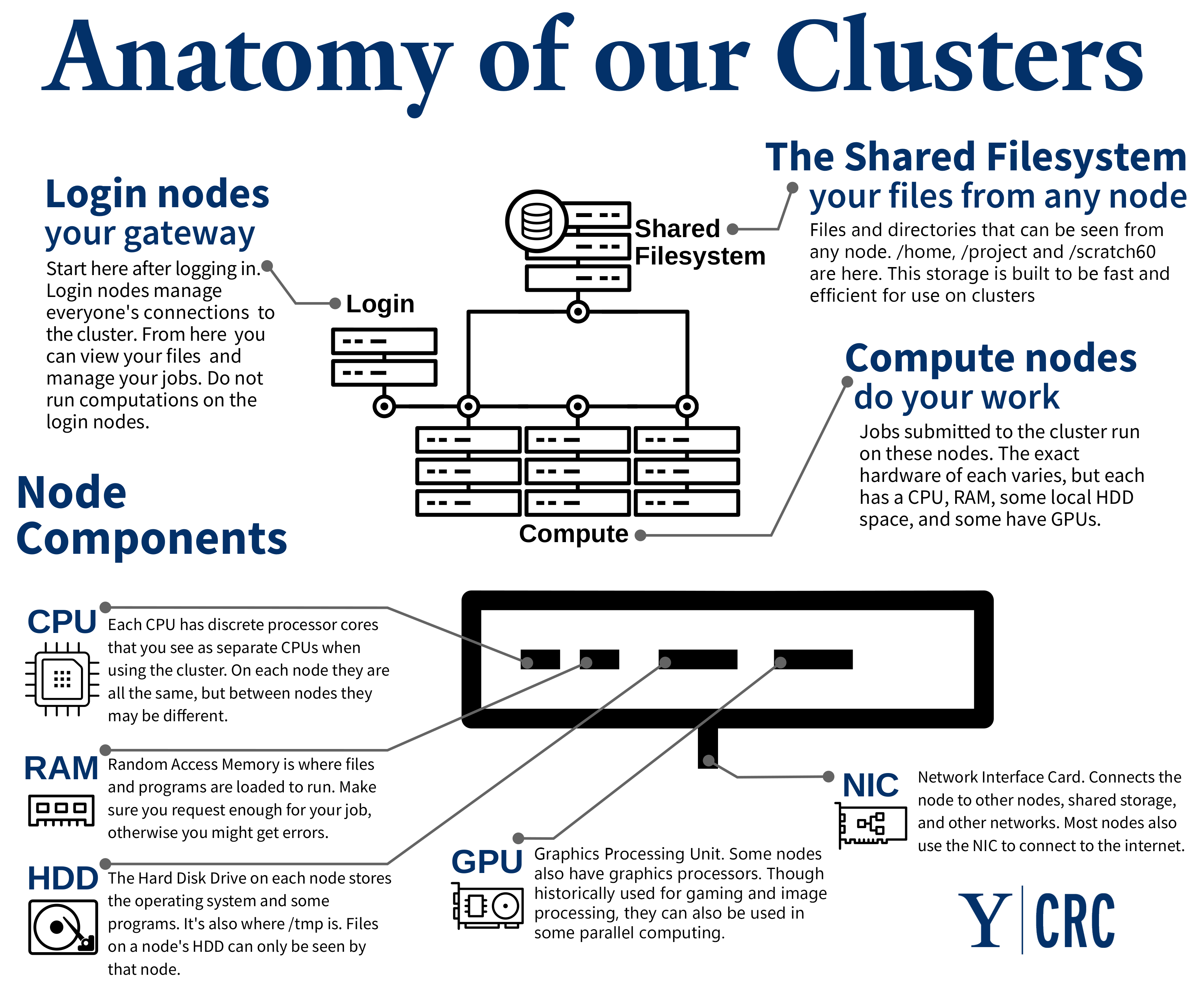
Broadly speaking, a high performance computing (HPC) cluster is a collection of networked computers and data storage. We refer to individual servers in this network as nodes. Our clusters are only accessible to researchers remotely; your gateways to the cluster are the login nodes. From these nodes, you view files and dispatch jobs to other nodes across the cluster configured for computation, called compute nodes. The tool we use to manage these jobs is called a job scheduler. All compute nodes on a cluster mount a shared filesystem; a file server or set of servers store files on a large array of disks. This allows your jobs to access and edit your data from any compute node. See our summary of the compute and storage hardware we maintain, from which you can navigate to a detailed description of each cluster.
Request an Account
The first step in gaining access to one of our clusters is to request an account. All users must adhere to the YCRC HPC Policies. To understand which cluster is appropriate for you and to request an account, visit the account request page.
Be a Good Cluster Citizen
While using HPC resources, here are some important things to remember:
- Do not run jobs, transfers or computation on a login node, instead submit jobs.
- Similarly, transfer nodes are only for data transfers. Do not run jobs or computation on the transfer nodes.
- Never give your password or ssh key to anyone else.
- Do not store any high risk data on the clusters, except Milgram.
- Do not run larger numbers of very short (less than a minute) jobs
Use of the clusters is also governed by our official guidelines.
Log in
Once you have an account, go to our Log on to the Clusters page login information and configuration.
If you want to access the clusters from outside Yale's network, you must use the Yale VPN.
Schedule a Job
On our clusters, you control your jobs using a job scheduling system called Slurm that allocates and manages compute resources for you. You can submit your jobs in one of two ways. For testing and small jobs you may want to run a job interactively. This way you can directly interact with the compute node(s) in real time. The other way, which is the preferred way for multiple jobs or long-running jobs, involves writing your job commands in a script and submitting that to the job scheduler. Please see our Slurm documentation or attend the Introduction to HPC workshop for more details.
Use Software
To best serve the diverse needs of all our researchers, we use software modules to make multiple versions of popular software available. Modules allow you to swap between different applications and versions of those applications with relative ease.
We also provide assistance for installing less commonly used packages. See our Applications & Software documentation for more details.
Transfer Your Files
You will likely want to copy files between your computer and the clusters. There are a couple methods available to you, and the best for each situation usually depends on the size and number of files you would like to transfer. For most situations, uploading files through Open OnDemand's upload interface is the best option. This can be done directly through the file viewer interface by clicking the Upload button and dragging and dropping your files into the upload window. For more information on this as well as other upload methods, see our transferring data page.
Introduction to HPC Tutorial
To help new cluster users navigate their first interactive and batch jobs, we have an Introduction to HPC tutorial to correspond with the topics discussed in our Introduction to HPC YouTube video.
Linux
Our clusters run the Linux operating system, where we support the use of the Bash shell. A basically familiarity with Linux commands is required for interacting with the clusters. We periodically run an Intro to Linux Bootcamp to get you started. There are also many excellent beginner tutorials available for free online, including the following:
Hands on Training
We offer several courses that will assist you with your work on our clusters. They range from orientation for absolute beginners to advanced topics on application-specific optimization. Please peruse our catalog of training to see what is available.
Get Help
If you have additional questions/comments, please contact us. Where applicable, please include the following information:
- Your NetID
- Cluster name
- Partition name
- Job ID(s)
- Error messages
- Command used to submit the job(s)
- Path(s) to scripts called by the submission command
- Path(s) to output files from your jobs